Sempre procuro me manter atualizado sobre as novidades do mercado de TI, sobretudo do mercado de dados. Tenho visto muita gente falando de Machine Learning, Deep Learning, Inteligência Artificial, Modelos Matemáticos, Data Science, etc.
Porém tenho uma preocupação com os novos data lakes, com dados sendo capturados por streaming e toda essa massa de informações que estamos persistindo e tentando tratar de forma muito rápida. Essa preocupação se baseia em como organizar os dados para que seu lago de dados não acabe se tornando um verdadeiro pântano de dados.
Durante o Big Data Week São Paulo 2019, assisti algumas palestras que corroboram com minha percepção. Dentre elas destaco:
Ricardo Sugawara que disse, em outras palavras, que se sua organização não tem a necessidade e/ou maturidade para uma solução de IA, permaneça no BI tradicional. Não vale a pena gastar energia para montar uma estrutura tecnológica cara se ela não será utilizada para trazer benefícios.
A Rubia Coimbra nos mostrou a “pirâmide de Maslow” da Cloudera e o Nielsen Rechia da AgiBank exibiu em sua apresentação uma outra “pirâmide de conhecimento”… para esses dois artefatos gostaria de observar o seguinte:
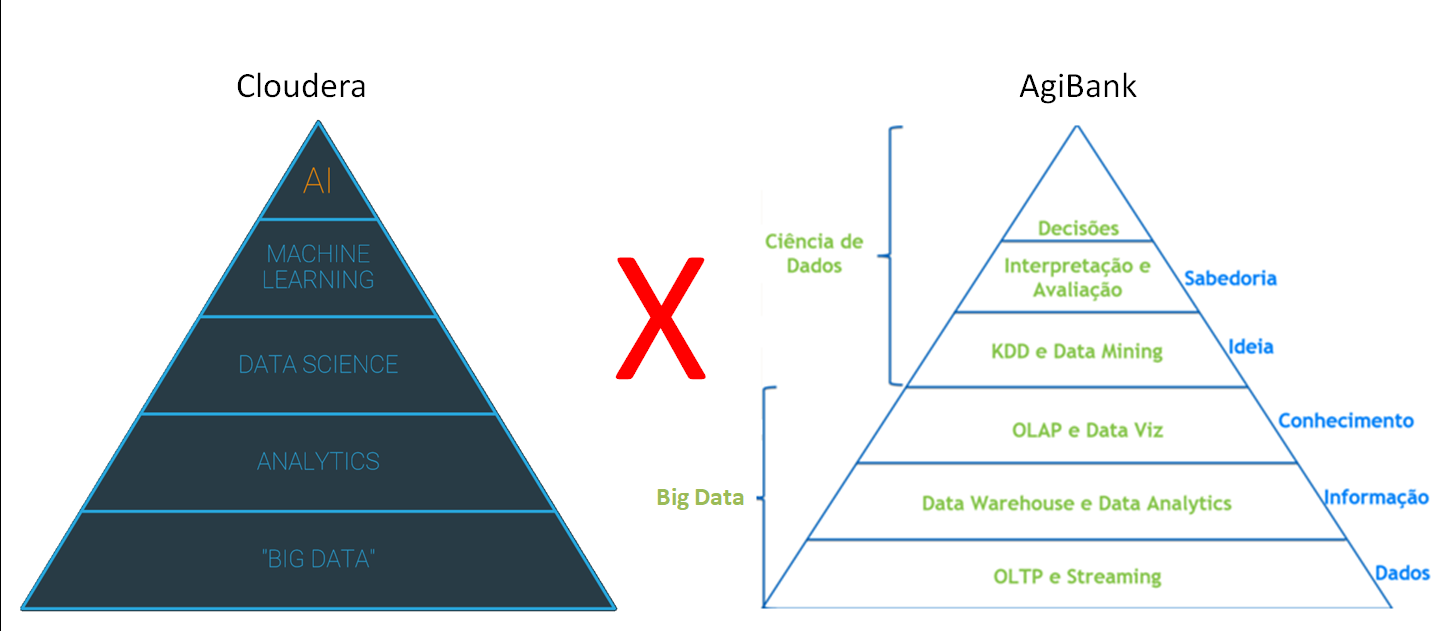
Notem que a base das pirâmides, embora usem nomenclaturas diferentes, falam basicamente da mesma coisa. A base para se alcançar a sabedoria envolve técnicas de analytics e DW. São as necessidades básicas dos dados, assim como para nós, seres-humanos, temos as necessidades fisiológicas. Não há como chegar ao topo com uma base fraca. Embora todos queiramos correr na frente dos concorrentes para extrair o máximo de competitividade que as novas tecnologias nos proporcionam, vale ressaltar que a tecnologia pro si só não traz resultados se não for aplicada com maestria, de forma correta e alinhada com os objetivos.
O número de fracassos de projetos de IA gira na casa dos 66%, ou seja, apenas um terço dos projetos é bem sucedido. Acredito que isso se deva ao fato de que muitos projetos estão queimando etapas ao pensar que conseguem trabalhar com dados não estruturados sem antes ter o conhecimento do que pode ser extraído com dados estruturados. Não estou sendo retrógrado. Sou de tecnologia e gosto dos avanços, mas se a Cloudera e o AgiBank já perceberam quais são as bases para chegarmos à sabedoria dos dados, por que não aprendemos com esses gigantes e evitamos fazer parte dos 66% que falham?
Este post é uma reflexão para os profissionais de dados. Thik about it!