Modelagem dimensional é uma técnica de projeto lógico normalmente usada para data warehouses que contrasta com a modelagem entidade-relacionamento. Segundo o prof. Kimball, a modelagem dimensional é a única técnica viável para bancos de dados que devem responder consultas em um data warehouse.
Esta é uma forma de modelagem onde as informações se relacionam de forma que podem ser representadas como um cubo. Sendo assim podemos fatiar este cubo e nos aprofundarmos em cada dimensão ou eixo para extrair mais detalhes sobre as informações que existem na empresa.
O que torna o Data Warehouse mais poderoso é que informações que se situam em vários sistemas, planilhas e arquivos espalhados por todos os setores da empresa, são reunidos em um banco de dados de forma dimensional, sendo assim tendo informações unificadas e padronizadas em um mesmo local.
Como exemplo, vejamos o caso de uma empresa que possui várias lojas filiais e que deseja acompanhar o desempenho de suas vendas ao longo do tempo. Um desenhista de Data Warehouse visualiza estas informações de uma forma como um cubo que pode ser descrito com três dimensões principais que são:
– Tempo
– Loja
– Produto
Na intersecção destas três dimensões está a quantidade (fato) de produtos que foi vendido.
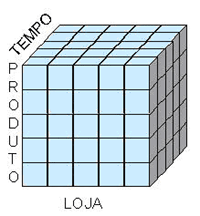
Neste modelo cada cubo menor, ou seja, a intersecção entre as dimensões ou eixos representa uma quantidade de um produto que foi vendido em uma determinada loja em uma data especifica.
Imagine agora se quisermos saber quais desses produtos que foram vendidos participavam de alguma promoção. Teríamos que ter mais uma dimensão chamada PROMOÇÃO, e se quisermos controlar em cada momento as equipes de marketing que atuaram em cima das promoções e das lojas devemos ter mais outra dimensão, e se quisermos controlar os clientes que compraram os produtos teríamos que ter uma dimensão Clientes, sendo assim teríamos um modelo com seis dimensões. Um modelo dimensional pode ter quantas dimensões forem necessárias.
Este modelo é extremamente simples, isto facilita para os usuários deste banco de dados identificarem onde estão localizadas as informações e permite que os softwares naveguem por estes bancos de dados com eficiência. Um outro fator importante para a modelagem dimensional é a velocidade de acesso a uma informação, com modelos simples sem muitas tabelas para relacionar, é muito rápido para extrair as informações necessárias.
Um modelo dimensional conta basicamente com uma tabela de fatos central e tabelas dimensionais ligadas diretamente a ela.
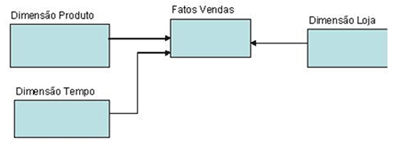
Os Fatos e Dimensões são tabelas do banco de dados, só que no modelo dimensional adquirem nomes de Fatos e Dimensões de acordo com a função da tabela.
Uma tabela de Fatos, em nosso exemplo “Fatos Vendas” contém medidas (métricas, valores) sobre o negócio como a quantidade de produtos que foi vendido, contém o valor da venda e o valor unitário do produto vendido. Além destas informações de fatos, esta tabela contém chaves para as tabelas de dimensões. Uma tabela fato (daqui para frente a chamaremos assim) é extremamente grande referente à quantidade de registros que contém, neste exemplo ela armazena todas as vendas de cada produto feitas em cada loja todos os dias. É comum uma tabela de fatos alcançar alguns Gibabytes logo nos primeiros meses de uso do Data Warehouse.
As tabelas de Dimensões contém descrições textuais sobre cada um elementos que fazem parte do processo, no exemplo que citamos temos três dimensões (Tempo, Loja e Produto) as tabelas dimensionais contém vários atributos que descrevem em detalhes todas as características que possam definir e serem úteis para futuras pesquisas no Data Warehouse.
A dimensão Produto deve ter descrições curtas e detalhadas sobre o produto, deve também ter o tamanho, peso, categoria, cor, departamento, marca, tipo da embalagem, etc. Ou seja todos os atributos que podem definir o produto e que possam ser utilizados para futuras pesquisas e analises que ajudarão o empresário a tomar decisões sobre seu negócio.
A dimensão Loja deve conter informações sobre as lojas que fazem parte do complexo do negócio, dentre estas informações deve ter descrições como endereço, CEP, região, cidade, bairro, telefone, gerente, etc.
A dimensão Tempo deve ter detalhes sobre o calendário para que facilite pesquisas estratégicas, então a dimensão tempo não deve ter somente a data em que o produto foi vendido, mas deve conter informações dia da semana, número do dia na semana, mês, número do mês no ano, ano, número da semana no ano, número de semanas corridas, número de meses corridos, trimestre, período fiscal, indicador de feriado, indicador de fim de semana, indicador de último dia do mês, etc.
Tipos de Modelos Dimensionais
– O Modelo Estrela (Star Schema)
No modelo estrela todas as tabelas relacionam-se diretamente com a tabela fato. As tabelas de dimensões não são normalizadas no modelo estrela, então campos como Categoria, Departamento, Marca contém suas descrições repetidas em cada registro, assim aumentando o tamanho das tabelas de dimensão por repetirem estas descrições de forma textual em todos os registros.

Este modelo é chamado de estrela porque a tabela de fatos fica ao centro cercada das tabelas dimensionais assemelhado a uma estrela. Mas o ponto forte a fixar é que as dimensões não são normalizadas.
– O Modelo Floco de Neve (Snow Flake)
No modelo Floco as tabelas dimensionais relacionam-se com a tabela fato, mas algumas dimensões relacionam-se apenas entre elas, isto ocorre para fins de normalização das tabelas dimensionais, visando diminuir o espaço ocupado por estas tabelas, então informações como Categoria, Departamento e Marca tornaram-se tabelas de dimensões auxiliares.
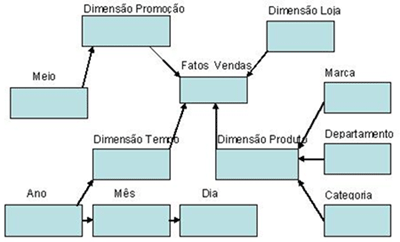
No modelo Floco existem tabelas de dimensões auxiliares que normalizam as tabelas de dimensões principais. Na figura anterior estas tabelas são (Ano, Mês e Dia) que normalizam a Dimensão Tempo, (Categoria, Departamento e Marca) que normalizam a Dimensão Produto e a tabela Meio que normaliza a Dimensão Promoção.
Construindo a base de dados desta forma, passamos a utilizar mais tabelas para representar as mesmas dimensões, mas ocupando um espaço em disco menor do que o modelo estrela. Este modelo chama-se floco de neve, pois cada dimensão se divide em várias outras tabelas, onde organizadas de certa forma lembra um floco de neve.
– Considerações sobre ambos modelos
O Modelo Snow Flake reduz o espaço de armazenamento dos dados dimensionais mas acrescenta várias tabelas ao modelo, deixando-o mais complexo, tornando mais difícil a navegação pelos softwares que utilizarão o banco de dados. Um outro fator é que mais tabelas serão utilizadas para executar uma consulta, então mais JOINS de instrução SQL serão feitos, tornando o acesso aos dados mais lento do que no modelo estrela.
O Modelo Star Schema é mais simples e mais fácil de navegação pelos softwares, porém desperdiça espaço repetindo as mesmas descrições ao longo de toda a tabela, porém análises feitas mostram que o ganho de espaço normalizando este esquema resulta em um ganho menor que 1% do espaço total no banco de dados, sendo assim existem outros fatores mais importantes para serem avaliados para redução do espaço em disco.